SJP SCI-TECH CLUB
Home
Student Research
Eel Grass Studies
Aquaponics Blog
Wind Energy Research
Deep Learning for BCI
Cloud Chamber Blog
And much more..
>
Bioluminesence
Lab Visits
Novartis Cambridge
Greentown Labs
MASS CEC
MIT Plasma Physics Center
Histogenics
US GreenBuild - Boston
Physics Olympics
Paper Airplanes
Glider Competition
Internships + More
Histogenics 2017
Home
Student Research
Eel Grass Studies
Aquaponics Blog
Wind Energy Research
Deep Learning for BCI
Cloud Chamber Blog
And much more..
>
Bioluminesence
Lab Visits
Novartis Cambridge
Greentown Labs
MASS CEC
MIT Plasma Physics Center
Histogenics
US GreenBuild - Boston
Physics Olympics
Paper Airplanes
Glider Competition
Internships + More
Histogenics 2017

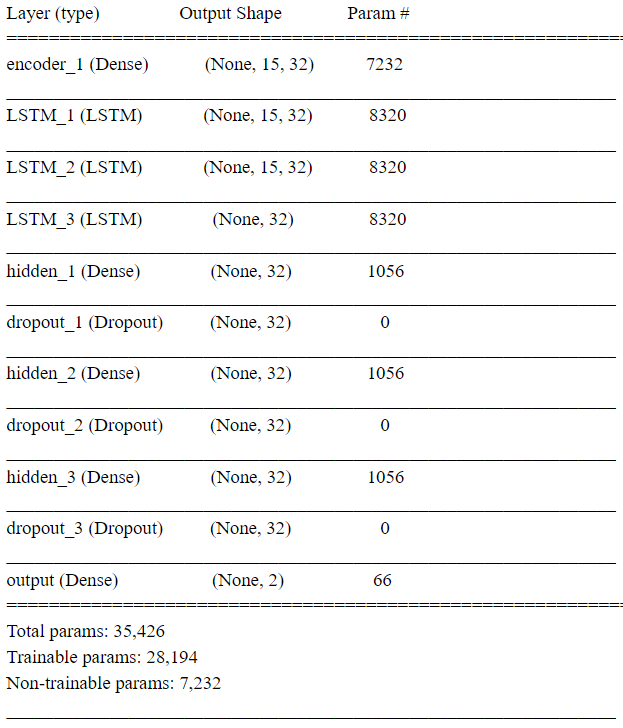
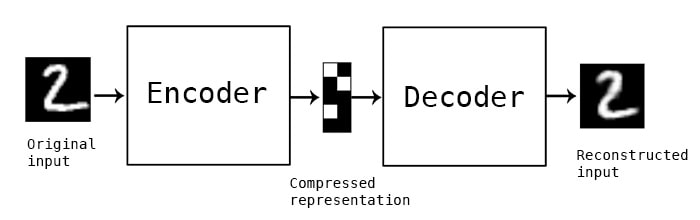
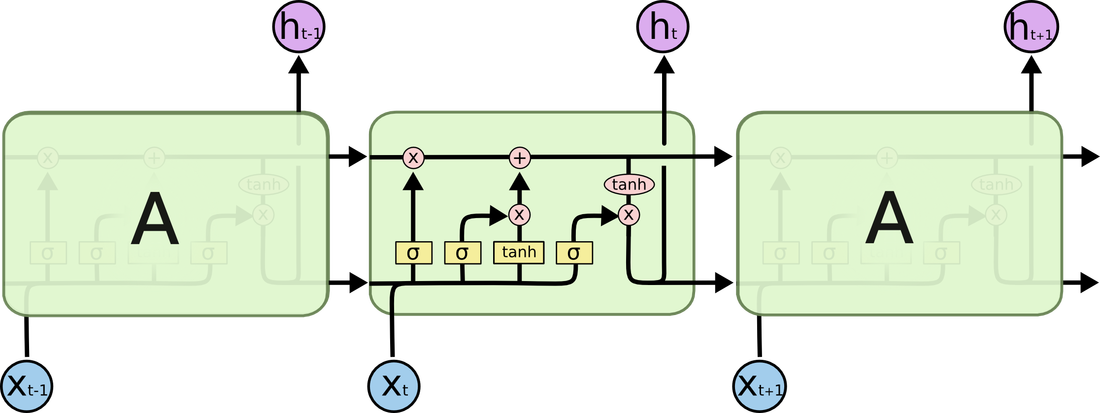
 RSS Feed
RSS Feed