
 Because different people have different patterns of brain signal, it is extreme difficult or nearly impossible to use the model trained by one person's brain activity for another person. However, the technique called transfer learning can make the algorithm remain stable. There were some researchers in the world applying the transfer learning to classical algorithms, such as SVM, but few people apply this technique to deep learning algorithms in the field of Brain Computer Interface. Designing a deep transfer learning algorithm can be the next step for my deep learning research.
Test Accuracy for the AE-LSTM-FFN Algorithm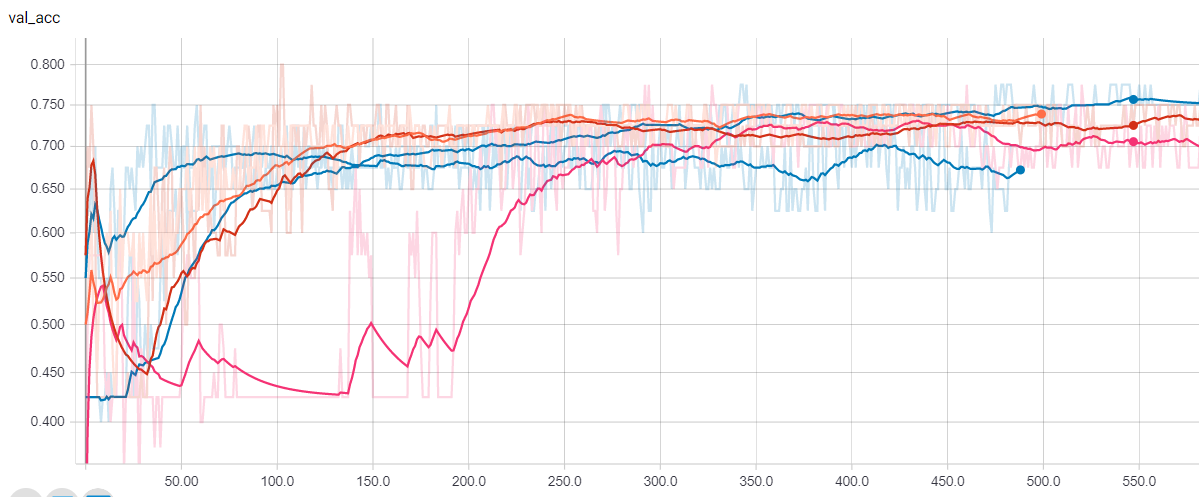 Test Accuracy for the Support Vector Machine algorithm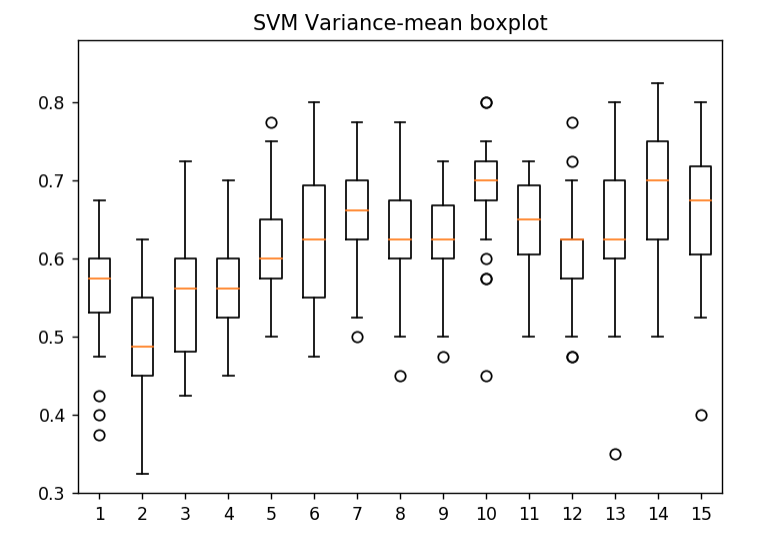 The best version of my algorithm achieves about 75% accuracy. The classical Support Vector Machine algorithm (SVM), however, has only 70% accuracy in average. In addition to the accuracy that my algorithm can achieve, it also has smaller variance, compared to the SVM. SVM algorithm has a variance around 20% in average, but my algorithm has only 5% variance due to the effectiveness of the autoencoder. In conclusion, the deep learning algorithm does outperform the classical algorithm.
2.1. Dataset: The data comes from BCI Competition IV (2008), datasets 2B . The dataset contains the brain activities of 9 different subjects. As the dataset description shown, “Three bipolar recordings (C3, Cz, and C4) were recorded with a sampling frequency of 250Hz. The recordings had a dynamic range of ±100µV for the screening and ±50µV for the feedback sessions. They were bandpassfiltered between 0.5Hz and 100Hz, and a notch filter at 50Hz was enabled. The placement of the three bipolar recordings (large or small distances, more anterior or posterior) were slightly different for each subject. The electrode position Fz served as EEG ground”. The recorded brain signals are then stored in the General Data Format. The GDF files can be loaded to Matlab using the BioSig toolbox. 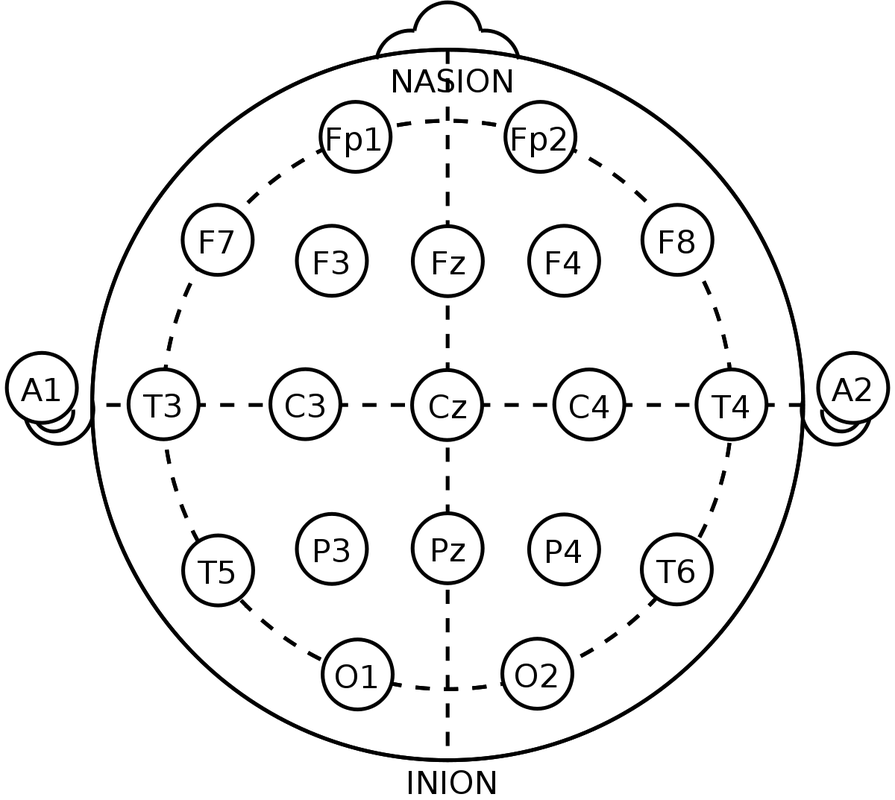 An AE-LSTM-FNN architecture for the non-invasive, motor imagery Brain Computer Interface system. 1. Why Non-invasive BCI: Compare to the invasive BCI, non-invasive BCI receives brain signal with much lower quality. Although the brain signal contain more noise, but the non-invasive BCI still has advantage over invasive BCI. Non-invasive BCI is more secure than the invasive one because the infection caused by implanting the sensors can be avoided. What’s more, the neurons near the sensors inside the brain will degraded as the time goes, then the sensors becomes ineffective. However, this will not happen when the subject is using non-invasive BCI. Moreover, because of the current low accuracy of non-invasive BCI, the system can still be improved as the classification algorithm becomes more and more advanced. 2. Why motor imagery: Unlike P300 and SSVEP that requires permanent attention to the external stimuli, motor imagery is independent of any stimulation and can be operated by users with free will. However, the motor imagery signal does has some disadvantages. The training costs a long time for users, may requiring several weeks or months. This is due to the brain tries to adapt Brain Computer Interface and produce more distinguishable pattern. The advanced algorithm can reduce the time of training. Architecture of Algorithm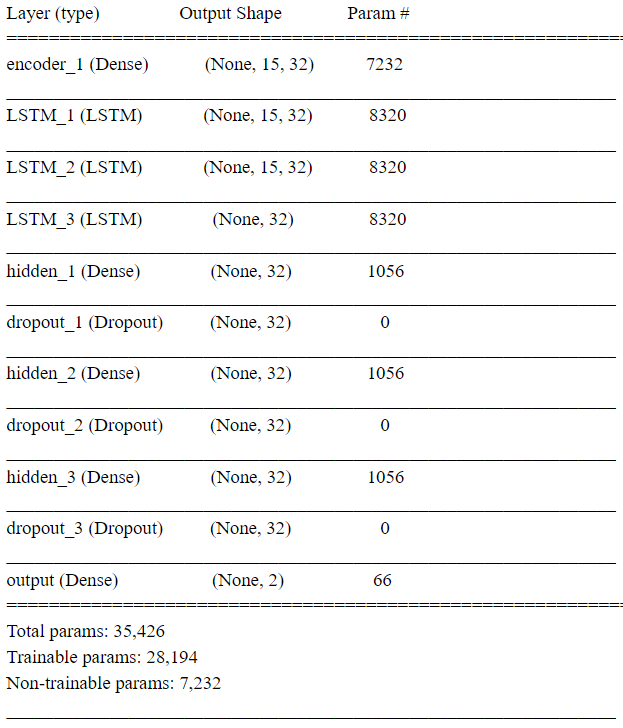 AutoEncoder: The Autoencoder is an algorithm that can reduce the noise and dimensionality of the sample. This is an unsupervised training algorithm, meaning this algorithm does not require the labels for learning the patterns of the datasets. In the case of Brain Computer Interface, the autoencoder does not need the intention of moving right or left arm the users thought to learn the patterns from their brain activities. An Autoencoder consists of two parts, the encoders and decoders. The encoders transform the original data into a compressed representation with much lower dimensions. Then, the decoders transform the compressed representation back to the representation with original dimension [10]. Autoencoders try to learn the weights of transformation that minimize the difference between original input and reconstructed inputs. Because the compressed representation has lower dimension, this encoding process is lossy. Therefore, the algorithm has to learn the weight that can preserve the information from the original input in lower dimension, resulting the compressed representation contain more useful information and less noise. 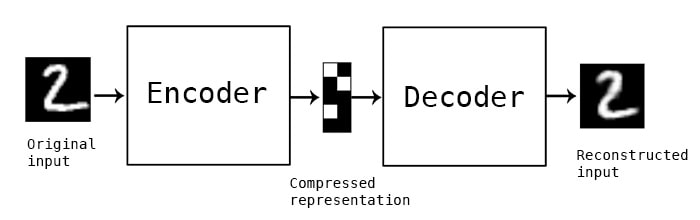 Long Short Term Memory: Long Short Term Memory is a deep learning architecture that has the ability to learn a pattern from a time series or a sequence data. LSTM was applied to the voice recognition tasks in the past, and classifiers achieved higher accuracy than most classicial algorithms. Because the LSTM will learn the pattern of the brain activity across all the time step, it is possible that applying LSTM to classify motor imagery EEG can improve the accuracy of the algorithm. 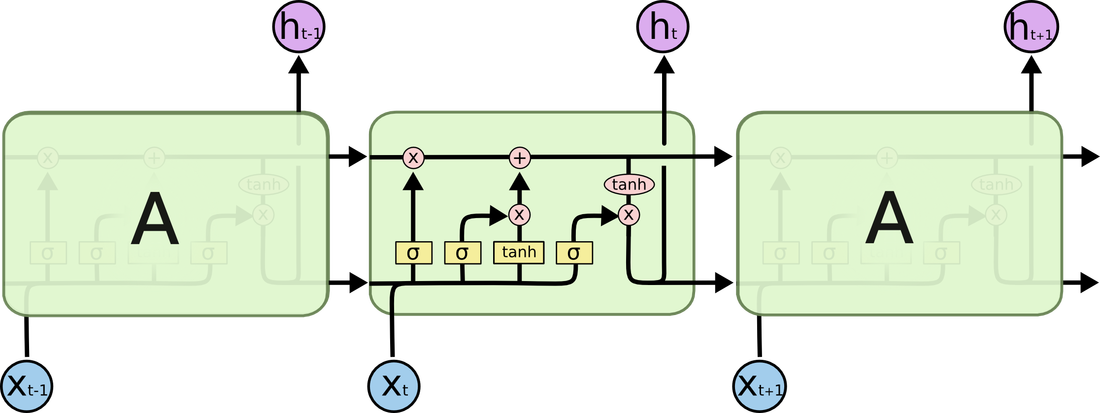 Deep Learning algorithms play a significant role in the field on image and speech recognition. Deep Learning is a part of the broad field of AI, inspired by the way neuron does the computation. Each node in the Deep Learning algorithm represents a neuron that receives a weighted sum of the input values from other neurons. Then, the neuron does a functional operation, applying a nonlinear function, such sigmoid, tan or relu to the weighted sum. It then sends the value produced by the nonlinear function to another neuron.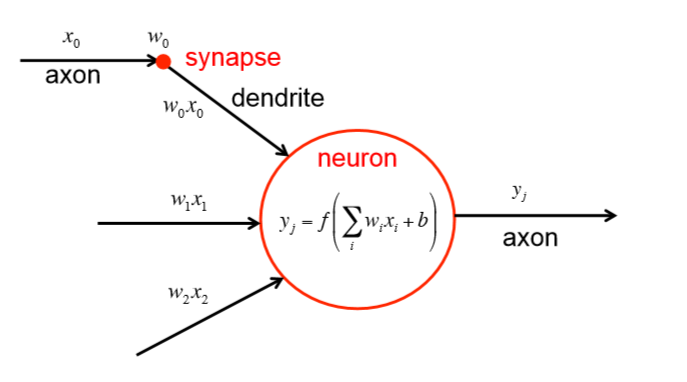 The brain computer interface, or the brain machine interface, is a hardware and software communication system that allows humans to control the external devices or interact with the surrounding by using their electric activity of the brains 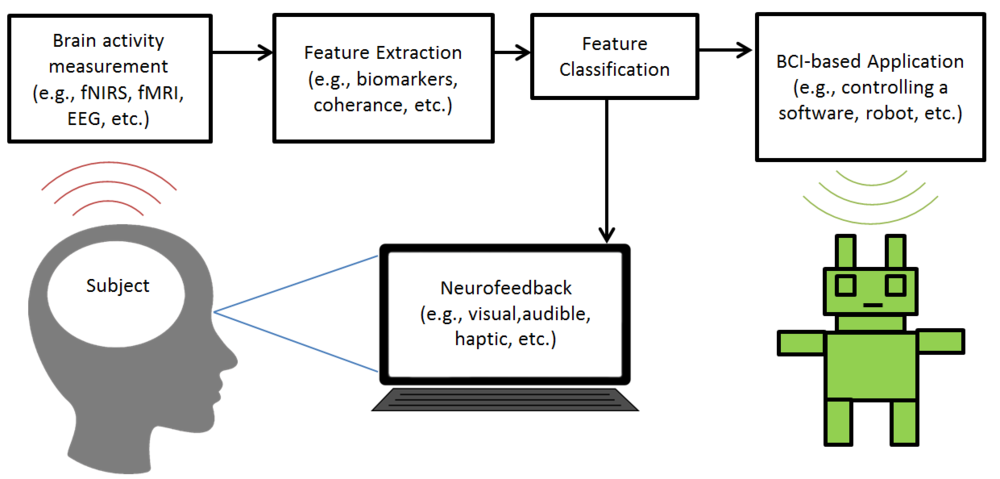 The main challenge of developing this BCI system is the difficulty of increasing the accuracy of the algorithm, because the BCI system can not easily distinguish what people intend to do.
|
AuthorJack Lin ArchivesCategories |
 RSS Feed
RSS Feed